|
 User Tools
User Tools 

Add support for a new language |
If you maintain support for a language mode in Emacs, or would like to be a maintainer for an unsupported language, then integrating the use of your language with CEDET can be a quick way to get some advanced features.
The tools in the CEDET Suite represent a lot of infrastructure, and have been designed to provide useful and clean interfaces to maintainers of different kinds of tools. Adding support for a language under CEDET can be challenging as the language will need to be "made to fit" a generic tagging infrastructure so that applications built on top of CEDET can work in a language agnostic way.
This document is set up to describe at a high level how to add support for a language, and is sorted so as maximize the number of features provided by your efforts.
Step 0: Join the mailing list |
The first thing to do is to join the cedet-devel mailing list. This is for two reasons:
- There might be someone already working with your language.
- The APIs for language support hooks is very wide, and the texinfo documentation for the more detailed aspects of language support are not very strong.
Step 1: Write a Grammar |
The most critical feature to start with is to write a tagging parser for CEDET for your language. The tagging system used by CEDET is in the tool called Semantic.
The very first step in this process is to make sure there is a traditional Emacs major-mode for the language. This major mode must have a robust and tested syntax-table that can correctly identify strings and comments, and has an accurate representation of all parenthetical expressions.
The next step is to choose how to parse your language. A parser for you language can take one of several forms.
Writing a lexer/grammar in Semantic
The most obvious tactic is to write a lexical analyzer, and a syntactic analyzer using Semantic. Within Semantic, there is a port of Bison called Wisent.
You should choose to use the Semantic lexer/grammer format for your language if it has a deterministic grammar. Often times you can download a pre-existing BNF grammar for a language. These BNF grammars can be converted to Wisent grammar format fairly easily.
Using the Semantic grammar format provides the greatest number of features to the CEDET tool suite.
Refer to the Semantic documentation for more on how to do this.
Write a regular-expression based tag generator
If the grammar of your file is irregular, or contains a lot of free-form text, you probably want to write a regular expression based tag generator.
Writing a regular expression based tag generator works fine with the Semantic tool set. You do not get the advantage of incremental parsing, or invalid syntax highlighting with these parsers.
To get started, the existing tag generators for Texinfo in cedet/semantic/semantic-texi.el is a good place to start. Be sure to read the Semantic guide on the TAG API to learn how to create and cook your tags.
Integrate an external parsing tool
You can also pull in an external tool like Exuberant CTags to parse your files. This can be handy to bootstrap support for your language. External parsing tools often have issues where the actual extents of the TAG in your buffer is unknown. They also have problems in that the buffer must be saved before they can work.
Adding an external parser can also be useful in conjunction with a semantic lexical analyzer/grammar. Files not in buffers can be parsed by the external tool, while in buffer files can be parsed by the internal grammar.
Exuberant CTags is already partially supported by Semantic. Extending ECtags support to new languages can be straight forward. See the file cedet/semantic/ctags/semantic-ectag-lang.el for an example of sh script support.
Step 2: Tune APIs with `mode-local' |
Once you have a good tagging system in place, many tools become enabled for your language. Tools such as tag decoration mode, stickyfunc mode, ECB code browser, and tag jumping are all enabled. In addition, the Semantic Database system will start storing and searching your tags.
The next step is to start tuning the infrastructure to your language. The only way to do this is dig in and start trying out different Semantic tools, and find out when things either don't look right, or don't behave property.
A simple place to start is with the command: semantic-test-all-format-tag-functions. This command will execute a range of functions that will format your tags in different ways. These routines are used in hundreds of places, and are a simple way to start learning about the mode-local tool, and how it works.
For example, in C, the basic way a tag name is formatted is
augmented so that if it is a function pointer, the syntax for that
is added to the name. The code in semantic-c.el looks
like this:
(define-mode-local-override semantic-format-tag-name
c-mode (tag &optional parent color)
"Convert TAG to a string that is the print name for TAG.
Optional PARENT and COLOR are ignored."
(let ((name (semantic-format-tag-name-default tag parent color))
(fnptr (semantic-tag-get-attribute tag :functionpointer-flag))
)
(if (not fnptr)
name
(concat "(*" name ")"))
))
Here are some functions you may need to override
- semantic-format-tag-* - Many functions in semantic-format.el are used throughout every tool in CEDET for converting tags into readable text strings. All the smart completion and tools use them.
- semantic-tag-ls.el - This file is full of overloadable functions for OO languages. Doing special implementations for these provides information about your OO language used by the formatting functions and the smart completion engine.
- semantic-tag-include-filename - Include tags should store file names in with the same text as appears in the sources. This will convert it to a live filename. For example, in Java you might convert "import java.lang.Foo;" into "java/lang/Foo.java"
- semantic-obtain-foreign-tag, semantic-insert-foreign-tag - These functions are used by tag copy/paste. If your language works closely with other languages, this lets you reformat tags from one language in a different way in another language. For example, cut a function from C, and insert it into Texinfo.
There are a wide array of functions to override for your language. If you have a hard time getting your language tuned, join the cedet-devel mailing list and find out more.
Step 3: EDE Support |
You may want to jump in and start getting the Smart Completion tool running. An important step before that is to get some basic EDE support up for your language.
EDE provides the infrastructure for how files relate to each other. The Smart Completion tool cannot work in a system involving multiple grouped directories if it cannot rely on EDE to provide this infrastructure.
If your language is typically used in a single directory, or if the links between files are explicity, you may be able to skip this step.
There are three possible ways to involve EDE.
Project.ede support
If your language uses Makefiles and compilers the way C does, then you can extend the ede-proj-obj.el infrastructure. It would likely involve creating a few compiler declarations and that's about it.
If your language is more complex, but still supported by AutoMake, then your job is a little more complex. There are several examples in either the Emacs Lisp support, or Texinfo support that you could use as examples.
Autodetect support
If your language's build system uses a set of predictable files, such as "Makefile.am", then you can write an EDE project that maps th EDE project structure onto your files. EDE's internal structure happens to make to directories and files, so you will need to find a way to do the same mapping. This will allow you to associate build commands to specific buffers.
The ede-emacs.el and ede-linux.el projects are very specific examples of how something like this might work.
Explicit configuration
You can also create EDE project wrappers that need to be explicitly created in a user's .emacs file. These are little easier to create and manage for the developer, but harder for a user to use. These are helpful if there are too many unpredictable ways to store and build your source code for your language, and provides an explicit place for users to have project local settings.
The ede-cpp-root.el project is a great example of how to build such a project.
Step 4: Context Parsing |
You probably still want to jump to the Smart Completion? Well, to do that, you need to get your language's local context parsing to work. The suite of functions is in semantic-ctxt.el. The code here allows basic movement withing your code, up and down nested code blocks, parsing local variables, and identifying scope modifiers, such as the C++ using statement.
Parenthetical languages like C or Java probably don't need a lot of work here. Non-parenthetical languages that have complex code constructs will need heavy customization.
A key function to start with
is semantic-get-local-variables. Try it out with
something like this:
M-: (semantic-get-local-variables) RET
The condensed output may be insufficient to examine the output. If
so, a helpful configuration for your .emacs file is:
(global-set-key "\M-:" 'data-debug-eval-expression)
Some other functions that are handy to have working are:
- semantic-up-context
- semantic-beginning-of-context, semantic-end-of-context
- semantic-beginning-of-command, semantic-end-of-command
Another important function suite to get right are the current-symbol set of functions. These are all core to the smart completion engine having something to complete. Try them out using M-:. The key ones are:
- semantic-ctxt-current-symbol
- semantic-ctxt-current-symbol-and-bounds
- semantic-ctxt-current-assignment
- semantic-ctxt-current-function
- semantic-ctxt-current-argument
Hopefully the logic in these key functions won't need to be overridden. They will, however, lead to other smaller scoped functions that you can override for your language. For example, you may need to provide values for, or override these:
- semantic-type-relation-separator-character - For structure dereferences. In C it would be . and ->.
- semantic-lex-syntax-table - You may have already configured this for parsing. Additional tweaks may be needed for context parsing.
Step 5: Smart Completion |
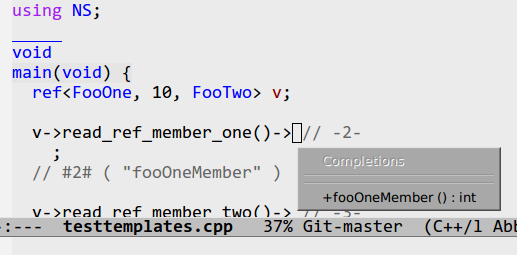 The next set of commands you may need to override for
you language is probably for the smart completion tool. Getting
this tool to work for you language is a tricky proposition, and
there are no hard and fast rules. You will need to try out the
different parts of the analyzer framework, and tune the output
results as needed.
The next set of commands you may need to override for
you language is probably for the smart completion tool. Getting
this tool to work for you language is a tricky proposition, and
there are no hard and fast rules. You will need to try out the
different parts of the analyzer framework, and tune the output
results as needed.
The completion engine is made of two key parts. There is
a Context Analyzer, and a Possible Completions
engine. The first thing is to try out the context analysis with
the command:
M-x semantic-analyze-current-context RET
It should then show a dump of what it found. For C++, it might
look like this:
Context Type: #
To get this information, it needs to derive a type cache
and a local scope. The type cache collects all the
datatypes known for the buffer and sorts them together for fast
lookups. It can be queried like this:
M-x semanticdb-typecache-dump
The output buffer is in 'Data Debug' mode, so use SPC to open up different lines to see what else is there.
The local scope then can learn about the classes and using
type statements, and put a Scope together. Query the scope like
this:
M-x semantic-calculate-scope
Once these two tools are producing rational output for your
language, then you can move back to debugging the analyzer. A
reasonable place to start is by using the command:
M-x semantic-analyze-debug-assist
This command will report everything it can find out about your context, with suggestions as to why it cannot identify a symbol under point.
Each of the above tools has a wide range of functions that can be
overriden. Some example functions that need customization for C
that are used by the completion engine are:
Once you get your first smart completion working, consider adding a new test file to semantic/semantic-ia-utest.el and putting your samples there. Re-running these tests will ensure you do not regress as you get more and more bits of the smart-completion engine working.
Step 6: Code Generation |
This step could also occur after your basic language parser is working. It does not need Smart Completion or EDE support, but does use some local context parsing.
Semantic's code generation system is
in SRecode, the Semantic Recoder. This
tool uses template files to specify basic structure for recoding
tags generated by your language grammar.
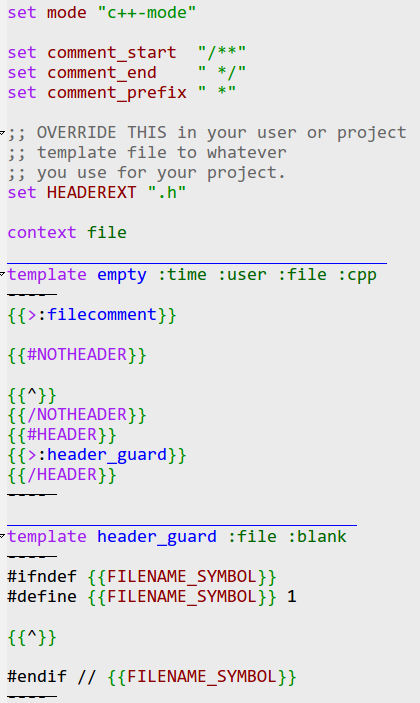
Use SRecode minor mode
Enable SRecode minor mode in your .emacs file.
(global-srecode-minor-mode 1)
Create a template file
The first step is to create a template file for your language, and add it to the SRecode template path. You can do this by putting your files in your ~/.srecode directory, or modifying the srecode-map-load-path to the location of your templates.
Now create an empty template file, such as srecode-LANG.srt. Use the SRecode minor mode to fill the buffer with C-c / /. It will prompt for the template to use, suggesting the empty template. Press RET to fill in the buffer.
A good start here is to create your own "empty" template. Creating an empty template is a great way to learn about quite a few SRecode template features, as you can include the default filecomment template, and learn about the :file and :user template arguments that fill in template macro values.
Create a custom template argument
The next step is to code up an argument for your language. In the image to the left, the :time and :user keywords are template arguments. They map to Emacs Lisp functions called srecode-semantic-handle-:time and srecode-semantic-handle-:user. These functions fill in the dictionary values calculated from the Emacs environment. Look at the argument handler srecode-semantic-handle-:cpp to learn more about how the FILENAME_SYMBOL is filled in as a C++ specific macro.
The next step is to start creating templates following the Semantic tag generation naming convention. See the SRecode info manual for more on this topic.
Application Templates
Some SRecode applications, such as the srecode-document-insert-comment command also have some custom templates that may need to be filled in. Adding support for any such application templates is the same as creating a generic set of templates. To do so, create a new template file, and fill it in, making sure to specify an application for that file.
